![[Spark] Spark Streaming(PySpark) - '배치 함수'를 작성하여 작업 경과 시간을 기록하고 Kafka로 발행하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FA0iL3%2FbtsCEK6gWjr%2FT2wBpBfDiFqiIM74VdC3G0%2Fimg.png)

🧐 개요
이전 포스트 - [Spark] Spark Streaming(PySpark)으로 Kafka 메세지 수신하기
이번 포스트는 저번 포스트에 이어서, Spark Streaming으로 Kafka에 메세지를 발행하는 다른 예제를 소개합니다. 구체적으로는 작업 경과 시간을 기록하여 Kafka로 발행하고자 합니다. 이번에는 해당 기능을 구현하는 과정에서 '배치 함수'를 만들어 각 배치별로 적용될 PySpark 가공 로직을 구성해보도록 하겠습니다.
(해당 기능은 추후 Grafana 대시보드에서 Kafka 스크립트의 동작 시간을 실시간 대시보드로 모니터링하기 위한 기능입니다. 해당 내용도 블로그에 포스팅하도록 하겠습니다)
🖍️ 예제 스크립트
간단한 pub/sub 기능을 구현하는 PySpark Streaming 예제 스크립트입니다.
해당 스크립트에서 제가 구현한 기능들은 다음과 같습니다.
- Streaming으로 Kafka 채널에 발행된 메세지를 읽고 터미널에 출력 - [기능 1]
- [기능 1] 작업에 소요된 시간을 기록하여 Dataframe으로 가공하고, 해당 데이터를 Kafka 채널에 발행 - [기능 2]
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
from time import time
conf = SparkConf().setAppName("streaming_pub_sub") \
.setMaster("spark://workspace:7077")
sparkContext = SparkContext(conf=conf)
spark = SparkSession(sparkContext=sparkContext)
kafka_bootstrap_servers = "localhost:9092"
input_kafka_topic = "hoonie"
output_kafka_topic = "hoonie_back"
checkpoint_dir = "file:///home/hooniegit/git/study/rdd-manufacture/demo/kafka/checkpoint"
def process_data(batchDF, batchId):
start_time = time()
transformed_df = batchDF.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
transformed_df \
.write \
.format("console") \
.option("checkpointLocation", f"{checkpoint_dir}/query1_checkpoint") \
.save()
end_time = time()
spent_time = float(f"{end_time - start_time:.2f}")
time_df = batchDF.drop("value") \
.withColumn("value", lit(spent_time))
time_df \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.write \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("topic", output_kafka_topic) \
.option("checkpointLocation", f"{checkpoint_dir}/query2_checkpoint") \
.save()
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("subscribe", input_kafka_topic) \
.load()
query = df \
.writeStream \
.foreachBatch(process_data) \
.start()
query.awaitTermination()
해당 기능을 구현한 전체 예제 스크립트입니다. 아래에서 세부적인 내용들을 하나씩 살펴보도록 하겠습니다.
1. Stream Dataframe 생성하기
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("subscribe", input_kafka_topic) \
.load()Stream Dataframe은 일반적인 Spark Dataframe에 Stream 관련 파라미터가 추가된 데이터프레임입니다.
spark.readStream 함수를 통해 Kafka 채널을 바라보고, 데이터의 발행시 데이터프레임을 생성하도록 구성할 수 있습니다.
서버 주소와 포트, 그리고 토픽 정보를 제외하면 해당 부분은 거의 그대로 스크립트를 사용하실 수 있습니다.
2. Query 정의 및 실행하기
query = df \
.writeStream \
.foreachBatch(process_data) \
.start()
query.awaitTermination()query는 실질적인 Spark 작업을 수행하는 작업 내역서입니다(같은 모양을 반복적으로 찍는 주형 틀 역할이라고 생각할 수 있습니다). query로 정의한 Spark 작업은 모든 Stream 배치에서 동일하게 동작하게 됩니다.
데이터프레임 가공 로직을 직접 입력할 수도 있지만, 각 배치별로 수행할 작업을 함수로 지정해주기 위해 .foreachBatch() 함수를 사용하였습니다. 이제 각 Stream 배치가 들어올 때마다 'process_data'라는 함수가 동작하게 됩니다.
3. Batch 함수 정의하기
def process_data(batchDF, batchId):
start_time = time()
transformed_df = batchDF.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
transformed_df \
.write \
.format("console") \
.option("checkpointLocation", f"{checkpoint_dir}/query1_checkpoint") \
.save()
end_time = time()
spent_time = float(f"{end_time - start_time:.2f}")
time_df = batchDF.drop("value") \
.withColumn("value", lit(spent_time))
time_df \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.write \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("topic", output_kafka_topic) \
.option("checkpointLocation", f"{checkpoint_dir}/query2_checkpoint") \
.save()배치 함수는 query로부터 해당 배치의 번호(회차) 정보와 해당 배치로 생성된 데이터프레임 정보를 동시에 받습니다. 따라서 함수를 정의할 때 batchDF와 batchID 정보를 requirements로 입력해주어야 합니다.
배치 함수 내에는 Spark 작업 내용을 정의해줍니다. 해당 스크립트에서는 읽은 데이터를 터미널에 출력하기까지 소요된 시간을 기록하여 Kafka 서버에 발행하고 있습니다.
Batch 함수 내에서 다루는 데이터프레임은 (스크립트 문법 상) Stream Dataframe이 아닌 일반적인 Spark Dataframe입니다. 따라서 메서드 사용 시 Stream 메서드를 사용할 수 없습니다(이 점을 중요하게 고려해주셔야 합니다). 예를 들어 기존에 사용하던 writeStream 대신 write를 사용하고, outputMode 등의 메서드를 제외해야 합니다.
0. 동작 테스트
작성한 어플리케이션의 동작 테스트를 수행하도록 하겠습니다. 지난 포스트에 언급했듯이, spark.sql.kafka 의존성 파일과 함께 pyspark-submit으로 스크립트를 실행해주셔야 합니다.
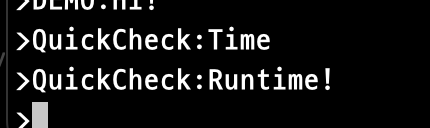
메세지는 QuickCheck 키값으로 Runtime! 메세지를 발행하였습니다.

Spark 어플리케이션이 정상적으로 동작하고 있는 것 같습니다. 우선 발행 데이터를 읽는 로직은 정상 동작하고 있습니다.
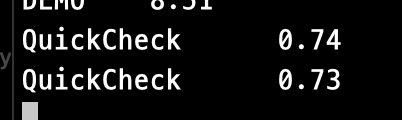
소요 시간을 기록해 발행하는 로직 역시 정상 동작하고 있습니다.
초 단위의 시간을 기록하고 있는데,수행하는 작업의 양 대비 소요 시간이 상당히 긴 것 같습니다.
📝 마치며
이전 포스트에서는 Spark Streaming 로직을 단일 스크립트에 전부 풀어서 실행하는 방식을 사용하였습니다. 이번 포스트처럼 각 배치가 실행할 함수를 따로 정의해둔다면, PySpark가 실행할 작업을 외부 경로에 모듈화하여 보다 체계적으로 관리할 수 있을 것입니다.
'데이터 이모저모 > Spark' 카테고리의 다른 글
| [Spark] Kafka Streaming - 인코딩 된 JSON 데이터 가공하기 (1) | 2024.01.06 |
|---|---|
| [Spark] PySpark의 기본 데이터 가공 프로세스 (1) | 2024.01.03 |
| [Spark] Spark Streaming(PySpark) - Kafka 메세지 가공 및 parquet 파일 저장하기 (1) | 2023.12.26 |
| [Spark] Spark Streaming(PySpark)으로 Kafka 메세지 수신하기 (0) | 2023.12.24 |
| [Spark] CPU 및 메모리 사용량 설정하기 (1) | 2023.12.22 |
발자취를 로그처럼 남기고자 하는 초보 개발자의 블로그
![[Spark] PySpark의 기본 데이터 가공 프로세스](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbIfC9j%2FbtsCTYkaiwQ%2FEROiDkoqGHE7I118HJC2F1%2Fimg.png)
![[Spark] Spark Streaming(PySpark) - Kafka 메세지 가공 및 parquet 파일 저장하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcnNYPF%2FbtsCELdk9fV%2Fd4aT8GYxxNSysCIrJDCs61%2Fimg.png)
![[Spark] Spark Streaming(PySpark)으로 Kafka 메세지 수신하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbqIpLd%2FbtsCBLj0fjg%2FpJK860c5LjXczHyXvpiefk%2Fimg.png)
![[Spark] CPU 및 메모리 사용량 설정하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbbizHu%2FbtsCw78KFmO%2FUnfs6xApufsKo8AtPdBOw1%2Fimg.png)