![[Spark] Spark Streaming(PySpark) - Kafka 메세지 가공 및 parquet 파일 저장하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcnNYPF%2FbtsCELdk9fV%2FAAAAAAAAAAAAAAAAAAAAABBGoViUrwyDBXNnOnbYyCRo0WjOAKiqZEa55HYBkU_O%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DdKz3FvMRfj5a8w2I%252Bf8J7fKGTtA%253D)

🧐 개요
이전 포스트 - [Spark] Spark Streaming(PySpark) - '배치 함수'를 작성하여 작업 경과 시간을 기록하고 Kafka로 발행하기
이전 포스트 - [Spark] Spark Streaming(PySpark)으로 Kafka 메세지 수신하기
이번 포스트는 지난 포스트에 이어, kafka를 통해 수신한 데이터를 가공하는 로직을 소개합니다. 해당 로직은 제가 데모를 돌리면서 실습한 부분이기 때문에 실제 현업에서의 사용 방식과는 차이가 있습니다. 이번 포스트에서 구현한 로직은 아래와 같습니다.
- Kafka에서 JSON 구조로 작성된 STRING 타입의 value 데이터를 발행
- Spark에서 value 데이터의 타입을 Struct 타입으로 변형
- Spark에서 데이터를 가공 후 기타 작업을 수행 (해당 스크립트에서는 parquet 파일을 저장)
🔎 배치 데이터의 구조 확인하기
Kafka를 통해 발생한 데이터는 아래와 같은 구조로 되어 있습니다.

Key 데이터로 날짜를 입력하고, Value 데이터로 딕셔너리를 입력하였습니다.
해당 데이터가 Spark Streaming 어플리케이션에 배치로 전달될 경우 아래와 같은 형식이 전달됩니다.
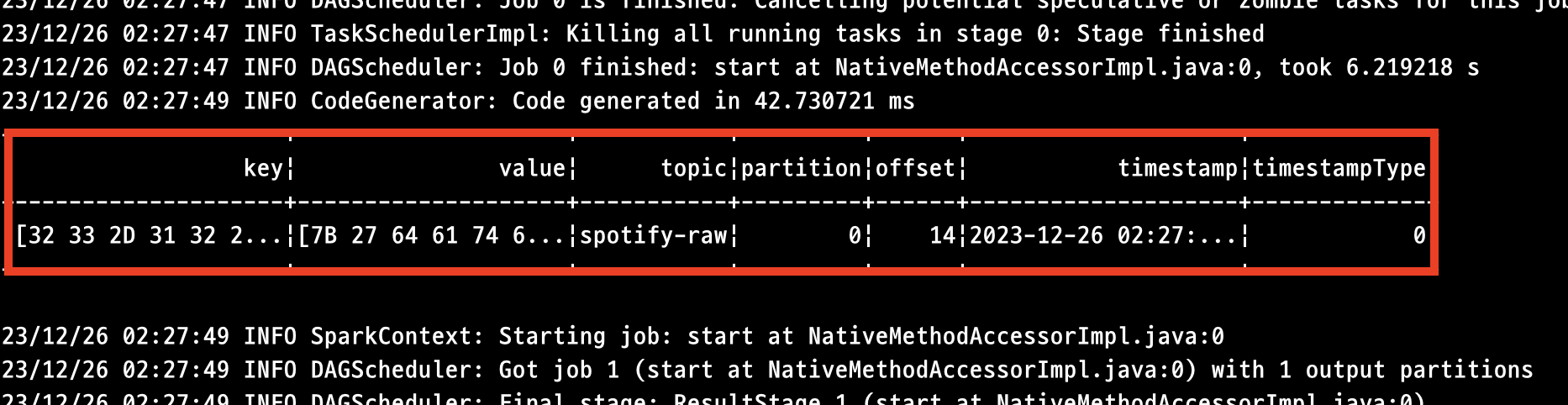
Kafka를 통해 발행된 메세지의 상세 규격이 표기되어 있습니다. 전송한 Key, Value 정보를 포함하여 Topic, Partition, Timestamp 등 세부적인 정보들이 모두 기재되어 있습니다.
Key 및 Value의 값이 인코딩/변환 되어있는 상태이기 때문에 추후 데이터 가공 과정에서 STRING 데이터 타입으로 CAST를 진행해주어야 합니다.
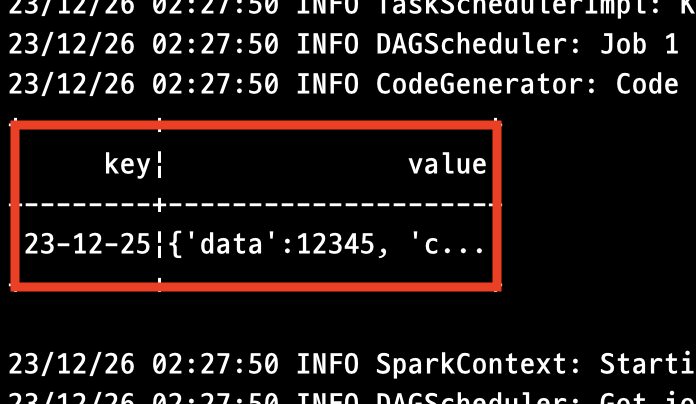
딕셔너리 데이터를 그대로 STRING으로 CAST하면 보내진 데이터가 그대로 출력됩니다. 이제 해당 Value 데이터의 타입을 딕셔너리로 변환한 후, 데이터 가공 작업을 수행해주어야 합니다.
🖍️ 스크립트 작성하기
query = df \
.writeStream \
.foreachBatch(process_data) \
.start()지난 포스트에서 설명한 바와 같이, 기능 구현은 foreachBatch() 내부에 배치 함수를 입력하는 방식으로 모듈화하여 구현하였습니다. 배치 함수에 입력되는 batchDF는 일반적인 Spark 데이터프레임의 구조를 가지고 있으므로 (Stream을 고려하지 않고) PySpark 작업을 거의 그대로 사용할 수 있습니다.
전체 스크립트 구조
def process_data(batchDF, batchId):
from pyspark.sql.functions import col, struct, expr, from_json
from pyspark.sql.types import StringType, StructType, IntegerType, StructField
from time import time
from pyspark.sql.functions import lit
kafka_bootstrap_servers = "localhost:9092"
input_kafka_topic = "spotify-raw"
output_kafka_topic = "spotify-record"
checkpoint_dir = "file:///home/hooniegit/git/Spotify-DemoProject/spark/checkpoint"
transformed_df = batchDF \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
try:
transformed_df_2 = transformed_df \
.withColumn("json_data", from_json(col("value"), StructType([
StructField("data", IntegerType(), True),
StructField("column_2", IntegerType(), True),
])))\
.select("key", "json_data.*")
try:
transformed_df_2 \
.write \
.mode('append') \
.parquet("file:///home/hooniegit/git/Spotify-DemoProject/spark/data/parquet")
except Exception as e:
print(f">>>>>>>>>>>>ERROR : {e}")
except Exception as e:
print(f">>>>>>>>>>>>ERROR : {e}")
transformed_df_2 = transformed_df기능을 구현한 전체 스크립트입니다. 아래에서 세부적인 내용을 살펴보도록 하겠습니다.
batchDF 데이터 CAST
transformed_df = batchDF \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")앞서 확인한 바와 같이, 배치 단위로 들어오는 데이터프레임은 내부 데이터가 변형되어있기 때문에 CAST를 통해 데이터 타입을 변경해주어야 합니다. 현재는 'key' 및 'value' 값만을 사용할 것이므로 2개의 컬럼을 SELECT하고 있습니다.
STRING 데이터 타입 변환 -> STRUCT
try:
transformed_df_2 = transformed_df \
.withColumn("json_data", from_json(col("value"), StructType([
StructField("data", IntegerType(), True),
StructField("column_2", IntegerType(), True),
])))\
.select("key", "json_data.*")
...
except Exception as e:
print(f">>>>>>>>>>>>ERROR : {e}")
transformed_df_2 = transformed_df해당 부분은 STRING 데이터타입의 컬럼을 STRUCT 데이터타입으로 변환하는 작업을 수행합니다. from_json 함수를 사용해 데이터 형식을 재정의하고 있습니다.
데이터 가공 로직 구현 시에는 예외 처리가 무척 중요합니다. Kafka 채널을 구독하는 Spark 어플리케이션을 동작할 때 초기에 빈 row를 가진 데이터프레임이 배치로 전달되기 때문에 반드시 예외 처리를 해 주어야 합니다. 해당 스크립트에서는 try & except 구문을 적극 활용하고 있습니다.
파일 저장 (to Parquet)
try:
transformed_df_2 \
.write \
.mode('append') \
.parquet("file:///home/hooniegit/git/Spotify-DemoProject/spark/data/parquet")
except Exception as e:
print(f">>>>>>>>>>>>ERROR : {e}")변환된 데이터프레임을 parquet 형태로 로컬 디렉토리에 저장하고 있습니다. 마찬가지로 빈 string 데이터에 대한 예외 처리 로직을 추가해야 합니다. 일반적인 PySpark 스크립트에서와 마찬가지로, 파일 저장 시에는 경로에 file:// 또는 hdfs:// 접두어를 추가해 디렉토리를 탐색할 환경을 지정해줍니다.
개선해야 할 부분
- 현재 스크립트는 단일 메세지를 단일 parquet 파일로 저장하고 있습니다. Spark는 파일을 저장할 때, 해당 작업을 수행하는 분할 파티션의 이름으로 파일을 저장하기 때문에 작업의 수에 비례하여 파일의 수가 증가하게 됩니다. 해당 로직을 개선하기 위해 UNION을 사용할 경우 단일 작업 수행에 지나치게 긴 시간이 소요되는 문제가 있으므로, 생성된 parquet 파일들을 압축하는 별도의 로직이 추가되어야 합니다.
- 현재의 로직으로 Struct 데이터 타입으로 변환하는 과정에서, 발행된 JSON 데이터의 스키마 구조가 복잡할 경우 해당 구조를 전부 파싱하여 데이터를 생성해야 합니다. 따라서 스크립트의 재사용성이 낮아진다는 단점이 있습니다.
📝 마치며
Stream 데이터프레임의 각 배치별로 배치 함수를 할당할 경우, 배치 함수에는 각 배치의 데이터프레임(batchDF)이 일반적인 Spark 데이터프레임 형식으로 들어옵니다. 따라서 일반적인 데이터 가공/분석 작업에 사용하던 다양한 PySpark 로직을 그대로 사용하여 확장성을 넓히고 모듈화를 진행할 수 있습니다.
'데이터 이모저모 > Spark' 카테고리의 다른 글
| [Spark] Kafka Streaming - 인코딩 된 JSON 데이터 가공하기 (1) | 2024.01.06 |
|---|---|
| [Spark] PySpark의 기본 데이터 가공 프로세스 (1) | 2024.01.03 |
| [Spark] Spark Streaming(PySpark) - '배치 함수'를 작성하여 작업 경과 시간을 기록하고 Kafka로 발행하기 (0) | 2023.12.24 |
| [Spark] Spark Streaming(PySpark)으로 Kafka 메세지 수신하기 (0) | 2023.12.24 |
| [Spark] CPU 및 메모리 사용량 설정하기 (1) | 2023.12.22 |
발자취를 로그처럼 남기고자 하는 초보 개발자의 블로그
![[Spark] Kafka Streaming - 인코딩 된 JSON 데이터 가공하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Ft6KLl%2FbtsC7pHSBni%2FAAAAAAAAAAAAAAAAAAAAAIWXu7BJsVmV1UYQ8dJVATrkgdKQGtMahbfMT8E2FbbH%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DBJ25eukbvJJUbMEwnJL9KtmN44o%253D)
![[Spark] PySpark의 기본 데이터 가공 프로세스](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbIfC9j%2FbtsCTYkaiwQ%2FAAAAAAAAAAAAAAAAAAAAANdvL6CVraULuHN1uguep_VqI41zH6WtevrNYA04LbJe%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3D4IADVO1iEAT%252B8YhJ3OJlZMY7B7M%253D)
![[Spark] Spark Streaming(PySpark) - '배치 함수'를 작성하여 작업 경과 시간을 기록하고 Kafka로 발행하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FA0iL3%2FbtsCEK6gWjr%2FAAAAAAAAAAAAAAAAAAAAAIsPm5wzN_N_aUWldI1eJuyWcUswpkZHfh47Tv5oDTSl%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3D7a8rO5fAlvmefzVGTu3UaJ5UdAQ%253D)
![[Spark] Spark Streaming(PySpark)으로 Kafka 메세지 수신하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbqIpLd%2FbtsCBLj0fjg%2FAAAAAAAAAAAAAAAAAAAAAMYrAZ_-zkOgBvoL00gO1KvRbKWlnvRyoa-nl9xSStJS%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DADeX4ogN81bUYNUNlskhhqP0apU%253D)